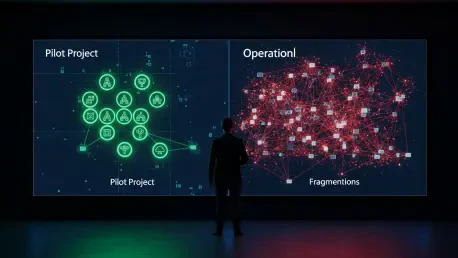

The promise of a hyper-connected world, driven by the Internet of Things (IoT), has captivated industries for years, with pilot projects demonstrating remarkable potential in optimizing everything from factory floors to city-wide logistics. However, a significant gap exists between the controlled environment of a pilot program and the chaotic reality of a full-scale production deployment. While data from The Eclipse Foundation’s “IoT and Edge Commercial Adoption Survey Report” shows that a solid 63% of organizations are actively deploying IoT solutions, a more sobering statistic reveals that less than half of these initiatives are considered successful when scaled to a large number of devices. This disparity highlights a critical truth: the most formidable obstacles to realizing the full value of IoT are often not rooted in technological deficiencies but in the immense, and frequently underestimated, challenges of operational reliability. As C-suite executives become more involved in these investment decisions, the pressure to transition from promising prototypes to profitable, large-scale operations intensifies, forcing a confrontation with the complex operational hurdles that can derail even the most innovative hardware projects.
Navigating the Escalating Complexities of Scale
The transition from a handful of devices to a fleet of thousands fundamentally changes the nature of the challenges an organization faces. Problems that are manageable or even nonexistent in a pilot phase can escalate into critical, system-wide vulnerabilities at scale. Two of the most significant constraints that intensify with growth are endpoint security and comprehensive observability, both of which require a strategic shift from manual intervention to automated, holistic management.
The Expanding Attack Surface
In a small-scale pilot, securing a dozen devices can often be handled with existing IT security protocols and manual oversight. However, as a deployment grows to thousands or tens of thousands of endpoints, the potential attack surface expands exponentially. Each new device represents another potential entry point for malicious actors, and the sheer volume makes traditional security measures impractical and ineffective. A major complication arises from the siloed nature of security management across different corporate domains. Information Technology (IT), Internet of Things (IoT), and Operational Technology (OT) environments frequently operate with distinct security tools, teams, and policies. This fragmentation creates dangerous blind spots where vulnerabilities can fester undetected. An attacker could potentially exploit a weakness in a connected OT sensor to gain access to the broader corporate IT network, or vice versa. To counter this, organizations must move towards a unified security posture that provides complete visibility and automated control across all connected assets, regardless of their domain. This requires solutions that can automatically enforce security policies, detect anomalies, and respond to threats in real-time across the entire hardware fleet, closing the gaps that siloed approaches inevitably leave open.
The Challenge of Observability
Effective management of any system depends on the ability to understand its internal state from its external outputs, a concept known as observability. For an IoT deployment, this translates to having detailed, real-time insights into device health, sensor accuracy, network connectivity, and overall performance. In a pilot project, if a device malfunctions, an engineer can physically inspect it or manually pull logs. At scale, this is an impossibility. Weak observability across a large fleet means that hardware issues can go unnoticed for long periods, leading to a gradual but significant erosion of the system’s effectiveness. For instance, a sensor might begin to drift, providing slightly inaccurate readings. While insignificant at first, this “data decay” can corrupt machine learning models, trigger false alerts, and lead to flawed business decisions. Without robust observability, it becomes exceedingly difficult to diagnose intermittent connectivity issues, track battery life degradation, or identify devices that are underperforming. The network becomes a black box, and operators are left reacting to major failures rather than proactively addressing minor issues before they cascade, ultimately undermining the reliability and value of the entire IoT initiative.
The Unseen Hurdles in Fleet Management
Beyond the high-level concerns of security and observability lie the granular, day-to-day operational tasks that become profoundly more complex at scale. Functions that are trivial for a small number of devices, such as updating software, can transform into logistical nightmares for a widespread fleet, revealing the hidden costs and complexities of long-term hardware management.
The Firmware Fragmentation Dilemma
Firmware management serves as a perfect illustration of an operational task that morphs from simple to daunting with scale. In a controlled pilot environment, deploying a firmware update is typically a straightforward process. An engineer can push the update to a few devices over a reliable network connection and quickly verify its success. When this process is applied to thousands of devices deployed in diverse real-world conditions, numerous failure points emerge. Network interruptions can cause an update to fail midway through, leaving the device in an unstable state. On-device storage limitations might prevent the new firmware package from being downloaded completely. A sudden power loss during the update process could “brick” the device, rendering it permanently inoperable without physical intervention. These individual failures, when multiplied across a large fleet, result in a condition known as firmware fragmentation. Instead of a uniform fleet running the latest, most secure software, the organization is left managing a chaotic mix of devices on various firmware versions, each with its own set of bugs, security vulnerabilities, and feature capabilities.
The Cumulative Impact of Small Failures
The initial impact of a single failed update or a minor hardware glitch might appear negligible, but the cumulative effect of these small, persistent failures is what ultimately compromises the long-term success of a large-scale deployment. Firmware fragmentation, for example, makes it nearly impossible to roll out new features uniformly across the fleet and dramatically complicates troubleshooting efforts, as support teams must contend with a multitude of different software environments. This operational drag slows down innovation and increases maintenance costs. The overarching consensus among organizations that have successfully navigated this transition is the importance of adopting a “slow and steady” approach. Rather than rushing to deploy as many devices as possible, successful companies prioritize building a robust operational foundation first. This involves implementing automated systems for update delivery with built-in rollback capabilities, establishing comprehensive device monitoring, and planning for failure scenarios from the outset. This deliberate, methodical focus on achieving predictability and operational resilience is what minimizes disruption and ultimately proves crucial for achieving sustainable success with large-scale hardware deployments.
Building a Foundation for Sustainable Growth
The journey from a successful IoT pilot to a thriving, scaled deployment was ultimately defined not by the novelty of the hardware but by the mastery of its operational lifecycle. Organizations that cleared this hurdle recognized early that the primary challenge was not a technical one but a logistical and strategic one. They understood that the methods used to manage ten devices in a lab were fundamentally unsustainable for managing ten thousand in the field. Consequently, these forward-thinking companies invested in building a robust operational backbone before they committed to a full-scale rollout. This involved implementing platforms that provided a single, unified view of the entire device fleet, automating critical tasks like security patching and firmware updates, and establishing deep observability to proactively monitor device health. This strategic foresight, which treated operational excellence as a prerequisite for growth rather than an afterthought, proved to be the definitive factor that separated triumphant, large-scale initiatives from those that remained perpetually stuck in pilot mode.







